Research Projects
Side-Channel Security
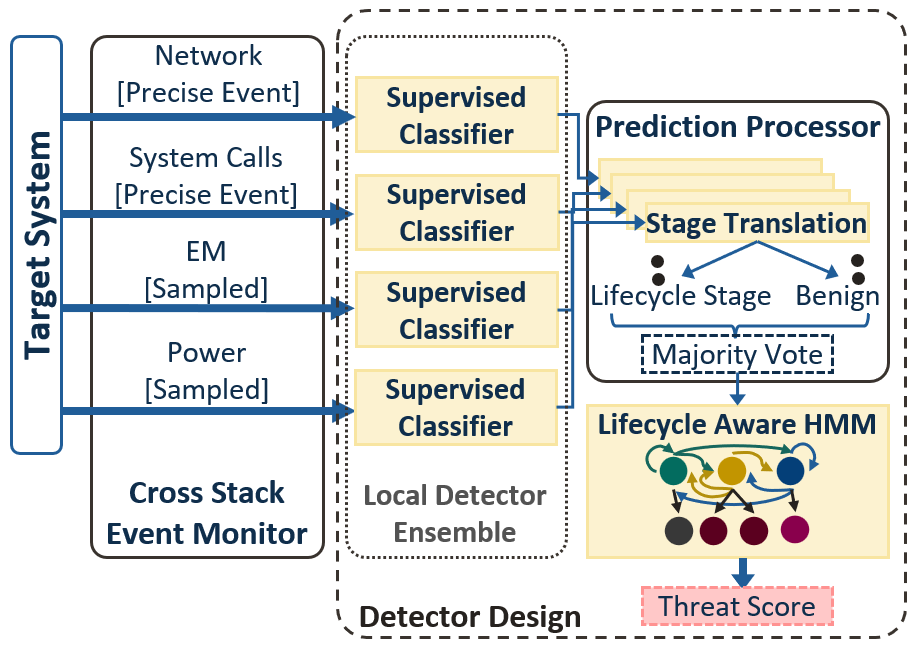
This project explores side-channels for attack and defense. On the attack side, we investigate novel methods to analyze and exploit vulnerabilities of embedded computer systems up to the software level. We particularly focus on the EM side-channel, which offers rich temporal and spatial information that expands the attack surface and thus provides unique challenges and opportunities in predicting vulnerabilities and extracting new types of information. On the defense side, we explore methods to improve behavioral malware detectors with a focus on power side-channels and other computer system signals. In particular, side-channel detection that mainly focuses on the execution phase of attacks often performs poorly in the presence of complex systems with noisy baseline behavior and potentially stealthy attacks. In practice, real-world exploits involve multiple distinct phases designed to prime and deliver an exploit and afterwards maximize post-execution persistence and reward. Lifecycle-aware (LA) detection leverages this contextual knowledge to improve detection confidence by correlating individual anomalies within the broader logic of a complete attack sequence, rather than in isolation.
Neuromorphic Computing System Co-Design
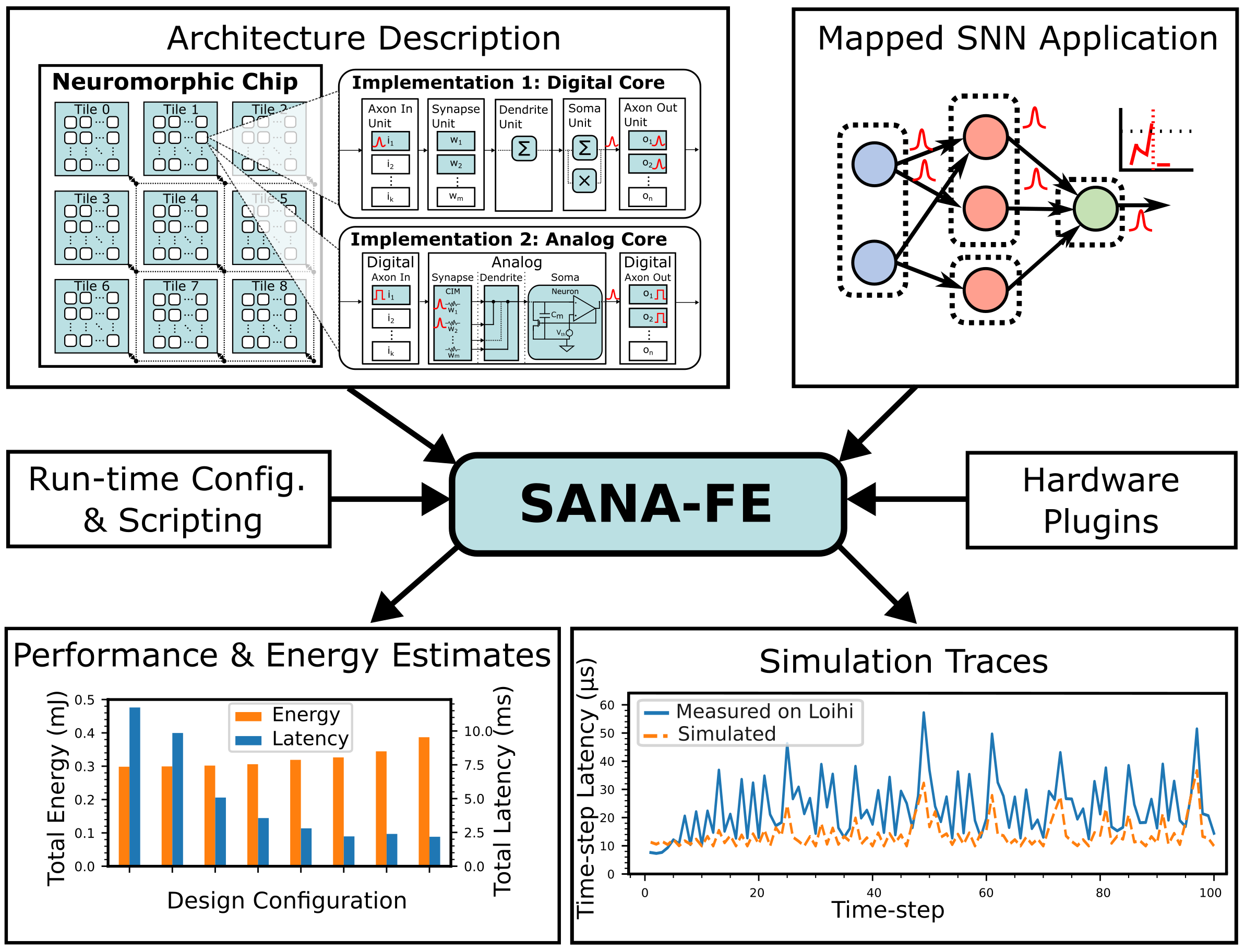
In this project, we explore methods and tools for co-design of spiking neural network (SNN)-based neuromorphic applications and architectures across the compute stack. A lack of tooling, in particular of modeling and simulations tools, is currently limiting these co-design opportunities. At the device and circuit level, we are developing flexible machine learning-based surrogate modeling techniques for fast and accurate functional, power, and performance modeling of analog compute blocks. At the architectural level, we have developed a novel neuromorphic architecture simulator called SANA-FE (Simulating Advanced Neuromorphic Architectures for Fast Exploration). SANA-FE can rapidly predict the power performance of various architectures executing user-provided SNNs, including hybrid analog/digital designs that incorporate analog compute blocks for efficiency in an overall digital backend for scalability.
Accelerator-Rich, Heterogeneous System Architectures
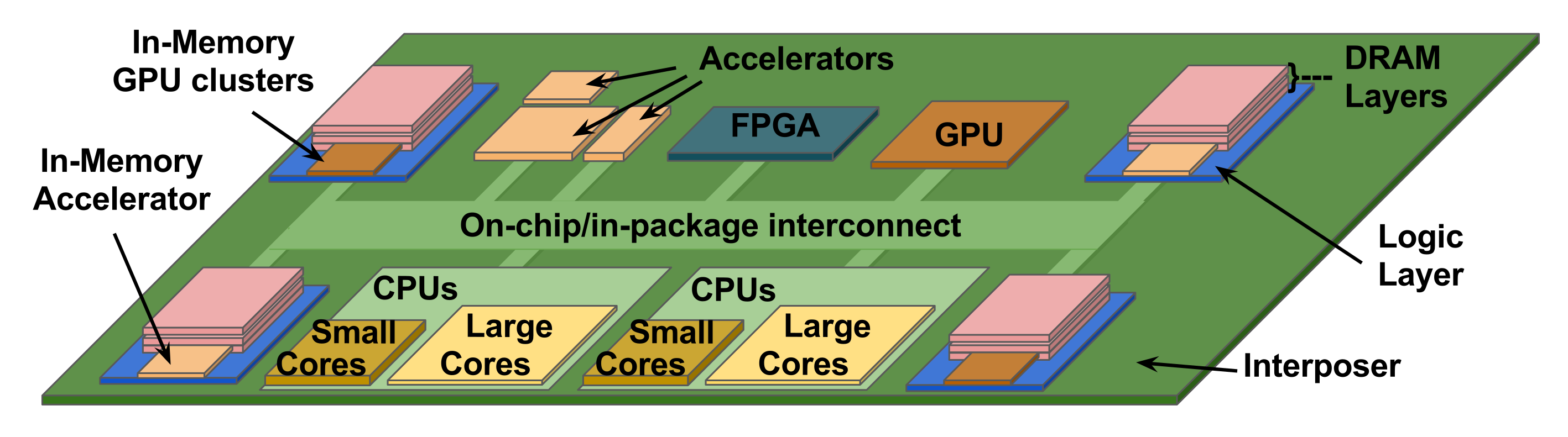
With architectural innovations and technology scaling reaching fundamental limits, energy efficiency is one of the primary design concerns today. It is well-accepted that specialization and heterogeneity can achieve both high performance and low power consumption, but there are fundamental tradeoffs between flexibility and specialization in determining the right mix of cores on a chip. Furthermore, with increasing acceleration, communication between heterogeneous components is rapidly becoming the major bottleneck, where architectural and runtime support for orchestration of data movement and optimized mapping of applications is critical. We study these questions through algorithm/architecture co-design of specialized architectures and accelerators for various domains, as well as novel architectures and tools for accelerator integration and heterogeneous system design.
Predictive Modeling for Next-Generation Heterogeneous Computer System Design
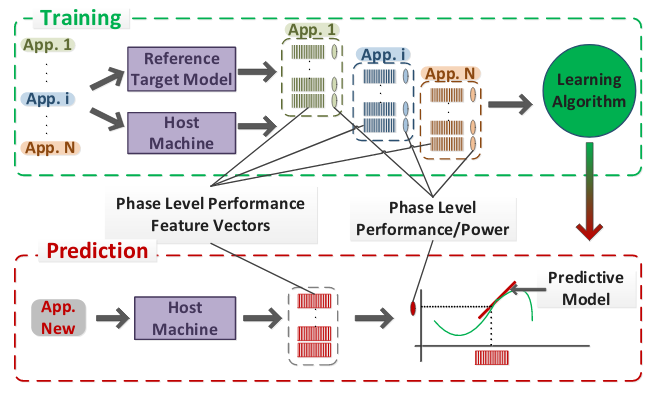
This project aims to investigate use of advanced machine learning-based, predictive methodologies to rapidly estimate the performance and power consumption of future generation products at early design stages using observations obtained on commercially available silicon today, specifically to aid in heterogeneous system design, programming and runtime management. Such techniques will allow efficient design cycles ensuring that the next-generation computing infrastructure meets the consumer and society’s needs. In addition, the project will be complemented by educational, outreach and active industry collaboration and technology transfer activities.
Network-Level Design of Cyber-Physical Networks-of-Systems
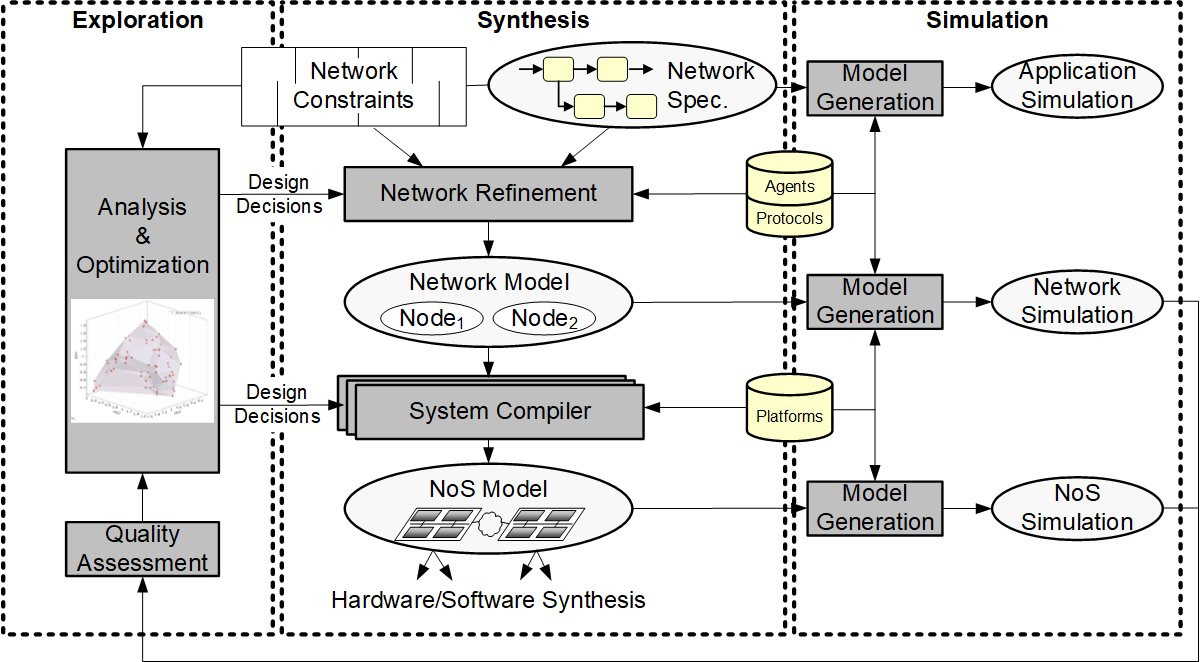
The broad vision of this project is to establish an integrated, comprehensive network-of-system (NoS) design environment as outlined in the figure on the left. At any level, a requirement for systematic design is the definition of a corresponding methodology that breaks the design flow into a necessary and sufficient sequence of steps. Formally, in each step, synthesis is a process of successive exploration and refinement that transforms a specification into an implementation under a set of constraints and optimization objectives.
Source-Level Simulation and Host-Compiled Modeling
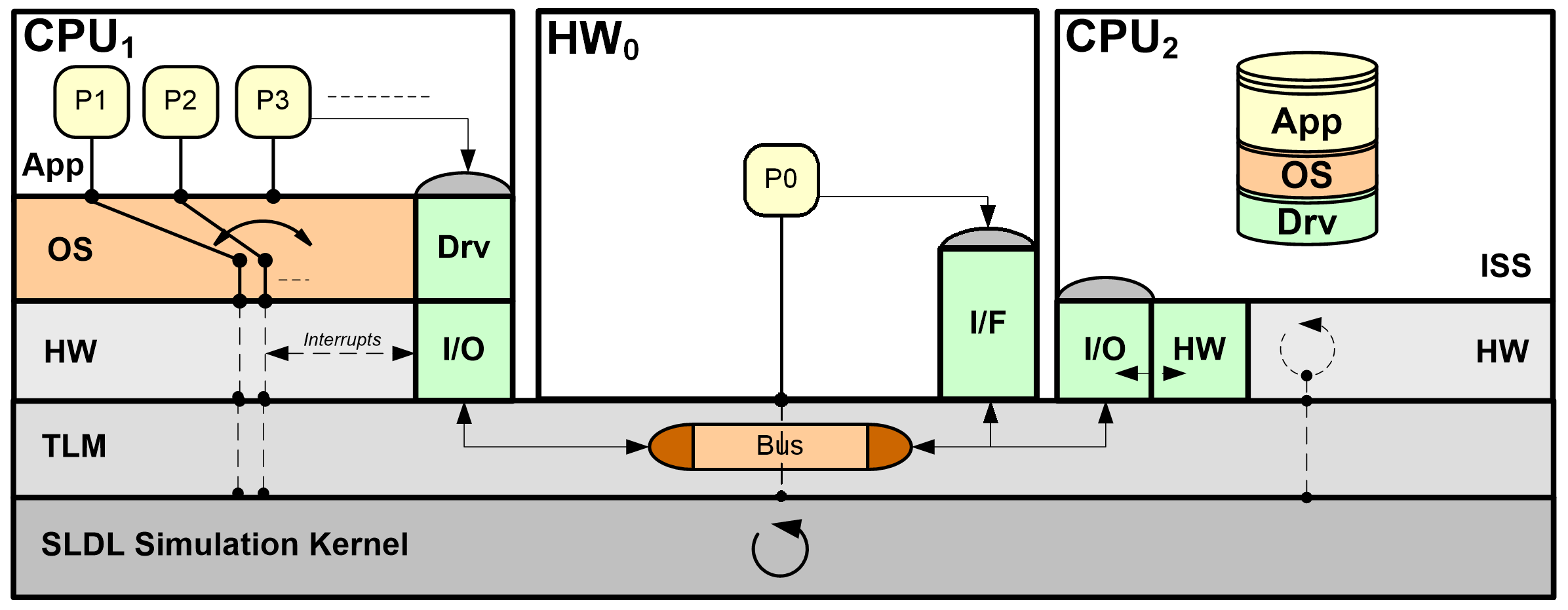
Simulations remain one of the primary mechanisms for early validation and exploration of software-intensive systems with complex, dynamic multi-core and multi-processor interactions. With traditional virtual platforms becoming too inaccurate or slow, we are investigating alternative, fast yet accurate source-level and host-compiled simulation approaches. In such models, fast functional source code is back-annotated with statically estimated target metrics and natively compiled and executed on a simulation host. So-called host-compiled models extend pure source-level approaches by wrapping back-annotated code into lightweight models of operating systems and processors that can be further integrated into standard, SystemC-based transaction-level modeling (TLM) backplanes for co-simulation with other system components.
Approximate Computing
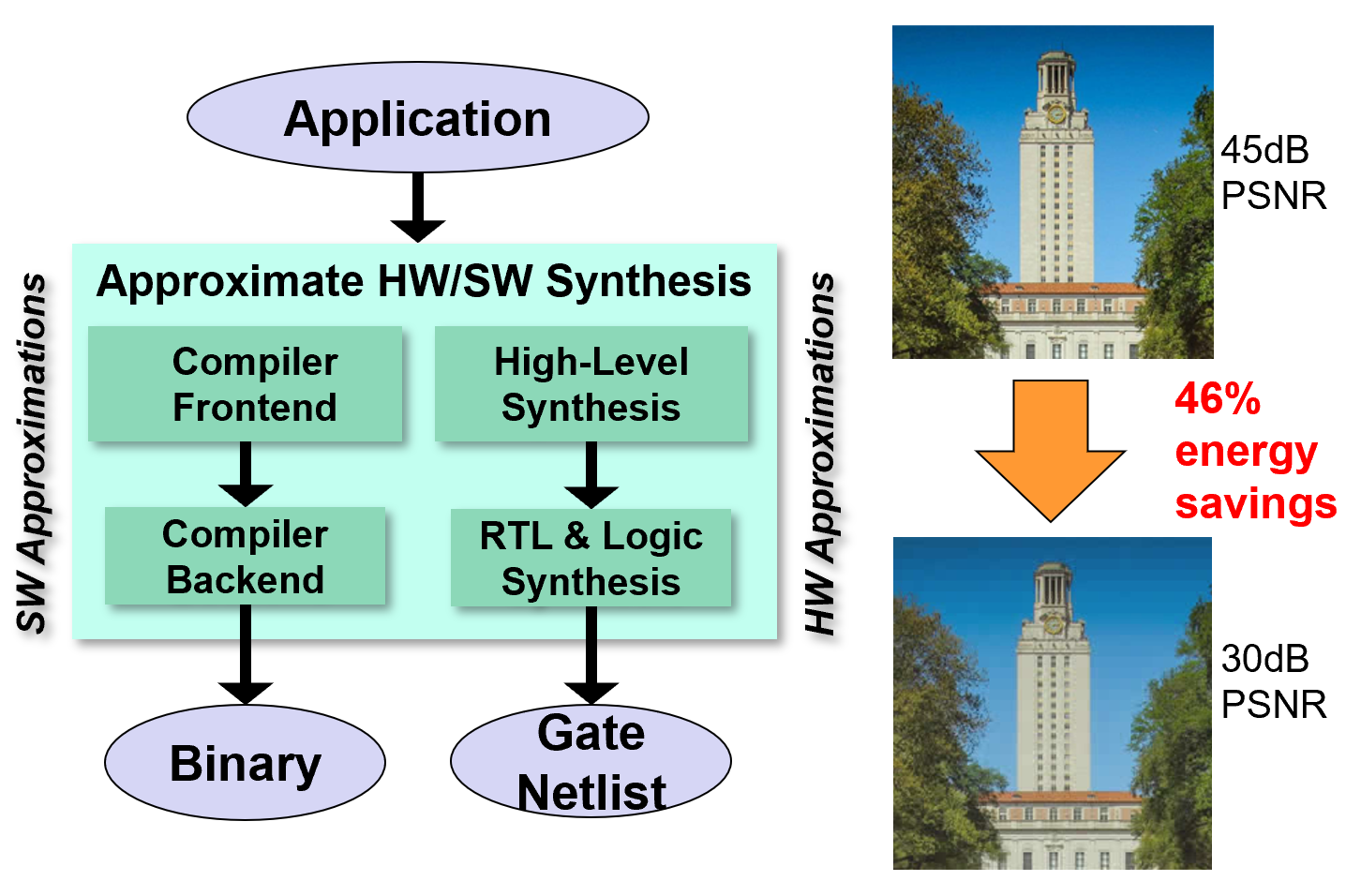
Approximate computing has emerged as a novel paradigm for achieving significant energy savings by trading off computational precision and accuracy in inherently error-tolerant applications, such as machine learning, recognition, synthesis and signal processing systems. This introduces a new notion of quality into the design process. We are exploring such approaches at various levels. At the hardware level, we have studied fundamentally achievable quality-energy (Q-E) tradeoffs in core arithmetic and logic circuits applicable to a wide variety of applications. The on-going goal is fold such insights into formal analysis and synthesis techniques for automatic generation of Q-E optimized hardware and software systems.